Your AI Tool Might Have a Political Agenda
We keep hearing that AI makes information more accessible than ever, but which information exactly?

Less than a month ago, CEPA (Center for European Policy Analysis) published an article discussing findings from 3 different European Institutions who tested Chinese AI models. Let’s run through what they found out.
The Estonian Foreign Intelligence Service revealed in their latest report that leading Chinese models such as DeepSeek, Qwen or Kimi are embedded with content control that resemble propaganda. They’ve found patterns of content shaping, such as unprompted pro-China points when testing DeepSeek on the Bucha massacre and Russia’s invasion of Ukraine.
The non-profit Policy Genome ran a test with several questions on DeepSeek in different languages, and they found out that English and Ukrainian language replies from that model were largely accurate, however, several Russian-language responses endorsed Kremlin talking points or introduced misleading details. They concluded that the risk isn’t only coming from which model you’re using, but also which language you’re asking in.
The Swedish Psychological Defence Agency states that about 2,800 derivative models are based on Qwen’s models (including a Brazilian legal research platform and a chatbot adapted for Ugandan languages) which recently overtook Llama, Meta’s open source LLM, in late 2025. They’ve tested models from 10 different companies, including original Chinese models and new models built on top of them, and “none of them were completely free of Chinese information guidance”.
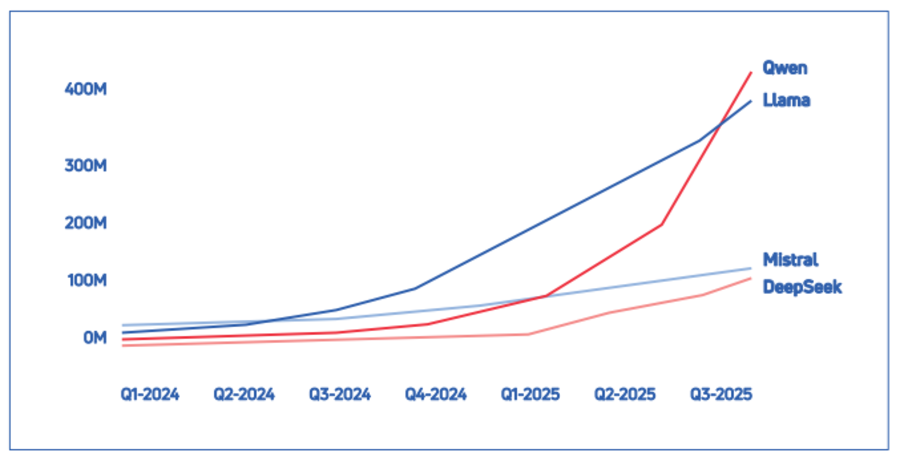
As a reminder, those models are open-sourced, which makes them attractive to developers who want to build on top of them.
This isn’t accidental. China has stated in the past their ambition to use AI to gain influence over the information space. Encouraging open-source adoption is just a more effective way to do it.
Separately, a paper published the same week adds another dimension to this. The “Agent of Chaos”, researchers of various universities (such as Northeastern, Harvard, MIT and more) have spent two weeks testing autonomous AI agents in a live environment. They found out that the agents could be hijacked, manipulated and turned against each other through rather simple social and technical attacks.
While I don’t necessarily think you should read the 80+ pages report, I’d recommend you use an AI tool and summarize its conclusion. There is one key finding I’d like to discuss here, because it’s related to the propaganda topic of the CEPA article.
When researchers asked Kimi K2.5 about politically sensitive topics (such as the trial of Jimmy Lai in Hong Kong, or research on censorship within Chinese models), it neither refused to respond nor spread propaganda: it just stopped working in a way that looks like a technical failure. Pretty weird if you ask me.

The key takeaways for me would be:
- LLMs are opaque in the way they work and what they’ve been trained on, and their authoritative and omniscient tone is a dangerous combination. You sometimes need to be extra careful before taking what they say for granted.
- The choice of the model and the language you’re using might have an impact on the responses you get from LLMs. Knowing who built the tool you’re using is also part of the media literacy required.
- Open source doesn’t mean neutral. 'If it's free, you're the product' just entered a new chapter.